# 2023 CCF 非专业级别软件能力认证第一轮(CSP-J)试题与解析
*信奥赛*
2023 CCF 非专业级别软件能力认证第一轮(CSP-J)试题与解析
## 目录
[TOC]
### 一、选择题(共15题,每题2分,共计30分:每题有且有一个正确选项)
#### 1. 在C++中,下面关键字中( )用于声明一个变量,其值不能被修改。
A. unsigned
B. const
C. static
D. mutable
> 常识 直接选择 B
#### 2. 八进制数(12345670)8和(07654321)8的和为( )。
A. (22222221)8
B. (21111111)8
C. (22111111)8
D. (22222211)8
> 转为 10 进制再求和然后转为 8 进制 也可以逢8进1
> 转换方法可以在 https://www.lingyuzhao.top/b/Article/-5001662716451593 文章中查看到
> 我们在这里使用的是逢8进1 因为这更好算
```
1 2 3 4 5 6 7 0
0 7 6 5 4 3 2 1
开始计算
0+1 = 1
7+2=9=8+1 凑出了一个8,进1放到下一次计算 本位是 1
1+6+3 = 9+1 = 8+2 凑出了一个8,进1放到下一次计算 本位是 2
1+5+4 = 9+1 = 8+2 凑出了一个8,进1放到下一次计算 本位是 2
1+4+5 = 9+1 = 8+2 凑出了一个8,进1放到下一次计算 本位是 2
1+3+6 = 9+1 = 8+2 凑出了一个8,进1放到下一次计算 本位是 2
1+2+7 = 9+1 = 8+2 凑出了一个8,进1放到下一次计算 本位是 2
1+1+0 = 1+1 = 0+2 没凑出8 不用进位,本位是2
最终答案 22222211 的8进制数值,选 D
```
#### 3. 阅读下述代码,修改data的value成员以存储3.14,正确的方式是( )。
```
union Data {
int num;
float value;
char symbol;
};
union Data data;
```
A. data.value = 3.14
B. value.data=3.14
C. data->value=3.14
D. value->data=3.14
> 联合体对象在调用方面和类对象是一样的,联合体对象指针和类对象指针调用也是一样的
> 在这里我们可以看到 data 没有被 `*` 修饰,因此是对象,不是指针 排除 C D
> 由于调用者是 data 中的 value 因此是 A
#### 4. 假设有一个链表的节点定义如下:
```
struct Node
{
int data;
Node* next;
};
```
现在有一个指向链表头部的指针:Node* head。如果想要在链表中插入一个新的节点,其成员 data 的值为 42,并使新节点成为链表的第一个节点,下面操作正确的是()。
A. Node* newNode = new Node; newNode->data = 42; newNode->next = head; head = newNode;
B. Node* newNode = new Node; head->data = 42; newNode->next = head; head = newNode;
C. Node* newNode = new Node; newNode->data = 42; head->next = newNode;
D. Node* newNode = new Node; newNode->data = 42; newNode->next = head;
> 链表的第一个节点 意味着 head 不再是第一个了,而是当前新节点的下一个,新节点就是包含这 42 数值的
> 因此我们需要先将新节点的下一个元素指向现在的 head 节点
> 其次需要给当前节点设置一个42的值
> 这样 新节点旧替代了曾经的 head 了!但是我们不要忘记最后一步,head 还没有更新呢,如果不更新,当前设置的 `newNode` 就丢了 因此选择 A
#### 5. 根节点的高度为 1,一棵拥有 2023 个节点的三叉树高度至少为( )。
A. 6
B. 7
C. 8
D. 9
> 三叉树的每层所含节点数量为 Cn=3×C(n-1) 其中 c 是节点数量,n是层数, 比如第一层节点只有1个,第二层有3个,第三层有9个节点,第四层有27个节点,第五层有27*3=81个节点
> 因此我们只需要直接代入公式计算节点数即可!
> 第六层有 81x3 = 243 算上之前的一共有 1+3+9+27+81+243 = 364个
> 第七层有 243x3=729 算是之前的一共有 364+729=1093个 前7层加一起数量还是不够
> 第八次有 729x3=2197 仅仅这一层就可以容下 2014 个节点了,因此就是选 C
#### 6. 小明在某一天中依次有 7 个空闲时间段,他想要选出至少一个空闲时间段来练习唱歌,但他希望任意两个练习的时间段之间都有至少两个空闲的时间段让他休息,则小明一共有( )种选择时间段的方案。
A. 31
B. 18
C. 21
D. 33
> 这是一道排列组合题,不过因为两个联系时间段之间至少两个空闲的时间休息,因此我们需要总结出一个可以计算出能用的时间段的数量的公式
>>预留间隔:
当我们选择 k 个时间段练习时,除了这 k 个时间段本身,我们还需要为它们之间的“至少两个空闲”要求预留空间。
具体来说,对于 k 个被选中的时间段,它们之间有 k-1 个“间隙”。
每个间隙至少需要 2 个空闲时间段。我们可以先“强制”在这 k-1 个间隙中各放置 2 个空闲时间段。这总共占用了 2(k-1) 个时间段。
这 2(k-1) 个时间段是专门用来“吸收”间隔约束的“虚拟”或“预留”空间。
> 接下来,我们计算出 k 在不通同情况下的剩下的可以用来进行组合的时间段数量
> k=1
>> 可以选择的时间段数量为 7-2(k-1)=7
>> 因此在个方案中只选择一个时间段的情况下,排列方案数量为 C(7,1)=7!/(1!×(7-1)!) =7
> k=2
>> 可以选择的时间段数量为 7-2(k-1)=5
>> 因此在个方案中只选择一个时间段的情况下,排列方案数量为 C(5,2)=5!/(2!×(5-2)!) = 120/12=10
> k=3
>> 可以选择的时间段数量为 7-2(k-1)=3
>> 因此在个方案中只选择一个时间段的情况下,排列方案数量为 C(3,3)=1
> 最终将这两种组合方案的方案个数进行求和为 7+10+1=18
#### 7. 以下关于高精度运算的说法错误的是( )。
A. 高精度计算主要是用来处理大整数或需要保留多位小数的运算
B. 大整数除以小整数的处理的步骤可以是,将被除数和除数对齐,从左到右逐位尝试将除数乘以某个数,通过减法得到新的被除数,并累加商
C. 高精度乘法的运算时间只与参与运算的两个整数中长度较长者的位数有关
D. 高精度加法运算的关键在于逐位相加并处理进位
> 分析C:错误。这是本题的错误选项。
对于最基础的模拟竖式乘法(即“小学乘法”算法),其时间复杂度是 O(n × m),其中 n 和 m 分别是两个乘数的位数。如果两个数位数相近,可以近似为 O(n²)。它显然与两个数的位数都有关,而不仅仅是较长者的位数。
虽然存在更高效的算法(如 Karatsuba 算法 O(n^log₂3),FFT-based 算法 O(n log n)),但这些算法的复杂度也依赖于两个输入的大小,且通常假设两个数长度相近。
关键词“只与...较长者有关”是绝对错误的。即使一个数非常短(比如个位数),另一个数很长,计算时间也主要由长数的位数决定,但严格来说,算法的步骤数仍然涉及两个数的交互。说“只与较长者有关”是过度简化且不准确的,尤其是对于标准的 O(n²) 算法。
#### 8. 后缀表达式 “6 2 3 + - 3 8 2 / + * 2 ^ 3 +” 对应的中缀表达式是( )。
A. ((6 - (2 + 3)) * (3 + 8 / 2)) ^ 2 + 3
B. 6 - 2 + 3 * 3 + 8 / 2 ^ 2 + 3
C. (6 - (2 + 3)) * ((3 + 8 / 2) ^ 2) + 3
D. 6 - ((2 + 3) * (3 + 8 / 2)) ^ 2 + 3
> 首先 我们可以知道 6-(2+3) 是最先进行的操作
> 然后 8/2+3 是下一步操作 到这里排除掉 B D
> 接下来我们继续看 是一个乘号,很显然是将 (6-(2+3) ) × (8/2+3) 的结果获取到
> 然后用结果进行 2次幂运算 最后 +3
> 符合的选择是 A
#### 9. 数 101010₂ 和 166₈ 的和为( )。
A. 10110000₂
B. 236₈
C. 158₁₀
D. A0₁₆
> 这题直接把 166 转2 或者把 101010转8 或者俩一起转10进制计算就好
> 在这我们使用的是直接把两个操作数转10进制,好算
> 2进制 101010 = 10进制 42
> 8进制 166 = 10进制 120
> 求和为 10进制的 162
> A 选项的10进制是 176
> B 选择的10进制是 158
> C 选择不用看 直接是错的
> D 选择 A 代表的是10 这里就是 10x16 和我们的预期一致,选择 D
#### 10. 假设有一组字符 {a, b, c, d, e, f},对应的频率分别为 5%、9%、12%、13%、16%、45%。以下选项中( )是字符 a, b, c, d, e, f 分别对应的一组哈夫曼编码。
A. 1111, 1110, 101, 100, 110, 0
B. 1010, 1001, 1000, 011, 010, 00
C. 000, 001, 010, 011, 10, 11
D. 1010, 1011, 110, 111, 00, 01
> 遇到这种题,我们需要记住一些知识
> 频率越低位越多
> 频率越高位越少
> 几个数字无法互相成为前缀
> 几个数字一般分布为 1 3 4 位,分别对应频率 高 中 低 三个情况
> 在本题中 f 频率最高,因此它位数最少,这里 A 很符合 但也不能说 B D C 不符合,我们继续判断
> 在本体中 a 频率最低,因此它位数最多,这里就只剩下 A 符合了,其它不用判断了
> 选择 A
#### 11. 给定一棵二叉树,其前序遍历结果为 ABDECFG,中序遍历结果为 DEBACFG。这棵树的正确后序遍历结果是( )。
A. EDBGFCA
B. EDGBFCA
C. DEBGFCA
D. DBEGFCA
> 关于树的遍历,查阅文章:https://www.lingyuzhao.top/b/Article/-1477114660675686
> 从前序遍历我们可以知道根节点是 A
> 在中序遍历中,可以将A的左右两边的子树提取出来
> 然后构建出左子树 `按照中序DEB` 构建树如下
```
E
D B
A
```
`按照中序CFG` 构建右子树如下
```
F
C G
A
```
最终我们需要将这两个子树 根据前序遍历顺序 合并到 A 根中
```
A
B C
D F
E G
```
> 然后根据这个树进行后序遍历
> 答案是 EDBGFCA 选择 A
#### 12. 考虑一个有向无环图,该图包含 4 条有向边:(1,2),(1,3),(2,4) 和(3,4) 以下选项中( )是这个有向无环图的一个有效的拓扑排序。
A. 4, 2, 3, 1
B. 1, 2, 3, 4
C. 1, 2, 4, 3
D. 2, 1, 3, 4
> 有效拓扑的题,解题逻辑就是根据有向边看看谁在前谁在后,比如这道题 1 在 2 3 的前面,排除 A D,然后 4 在 2 3 的后面 排除 C 答案为 B
#### 13. 在计算机中,以下选项中描述的数据存储容量最小的是( )。
A. 字节(byte)
B. 比特(bit)
C. 字(word)
D. 千字节(kilobyte)
> 如果需要获取内存地址,也就是能够获取到内存地址的最小的单位,这里是字节,位是不能的,位虽然很小
> 位是存储数据的最小单位,这里是存储容量最小的单位,选位是可以的
> 选择 B
#### 14. 一个班级有 10 个男生和 12 个女生。如果要选出一个 3 人的小组,并且小组中必须至少包含 1 个女生,那么有( )种可能的组合。
A. 1420
B. 1770
C. 1540
D. 2200
> 一道组合题 22个人选 3 个人为 C(22,3)=1540 中组合
> 然后 排除掉不符合的情况,就是 C(10,3) 10个男生里3个全男生的组合数 为 120
> 因此 1540-120 就是最终答案 选择 A
#### 15. 以下选项中不是操作系统的是( )。
A. Linux
B. Windows
C. Android
D. HTML
> HTML 属于类似编程的一种标签语言 不是操作系统 选 D
### 二、阅读程序(程序输入不超过数组或字符串定义的范围,判断题正确填√,错误填×;除特殊说明外,判断题每题 1.5 分,选择题每题 3 分,共计 40 分)
(一)阅读以下程序,完成相关题目。
```
#include <iostream>
#include <cmath>
using namespace std;
double f(double a, double b, double c) {
double s = (a + b + c) / 2;
return sqrt(s * (s - a) * (s - b) * (s - c));
}
int main() {
cout.flags(ios::fixed);
cout.precision(4);
int a, b, c;
cin >> a >> b >> c;
cout << f(a, b, c) << endl;
return 0;
}
```
假设输入的所有数都为不超过 1000 的正整数,完成下面的判断题和选择题。
#### 判断题
16,(2 分)当输入为“2 2 2”时,输出为“1.7321”。( √ )
> 16题可以直接代入 最后是对3开2次方根,可以用 1.7321 * 1.7321 看看是不是接近三
17,(2 分)将第 7 行中的“(s - b) * (s - c)”改为“(s - c) * (s - b)”不会影响程序运行的结果。( √ )
> 乘法前后顺序不影响结果
18,(2 分)程序总是输出 4 位小数。( √ )
> 因为 `cout.flags(ios::fixed);` 导致只有小数,不会有科学计数法
> 因为 `cout.precision(4);` 因此小数点后只有4位
>> 注意哦 整数不受影响 但是 f 返回是不是整数
#### 选择题
19,当输入为 “3 4 5” 时,输出为( )。
A. “6.0000”
B. “12.0000”
C. “24.0000”
D. “30.0000”
> 直接代入计算 s = (3+4+5)/2 = 6
> 然后计算 f(3,4,5) = 根号(6x(6-3)x(6-4)x(6-5)) = 根号(36)=6
> 选择 A
20,当输入为 “5 12 13” 时,输出为( )。
A. “24.0000”
B. “30.0000”
C. “60.0000”
D. “120.0000”
> 和上面一样计算就行了
### (二) 阅读以下程序,完成相关题目。
```
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int f(string x, string y) {
int m = x.size();
int n = y.size();
vector<vector<int>> v(m + 1, vector<int>(n + 1, 0));
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (x[i - 1] == y[j - 1]) {
v[i][j] = v[i - 1][j - 1] + 1;
} else {
v[i][j] = max(v[i - 1][j], v[i][j - 1]);
}
}
}
return v[m][n];
}
bool g(string x, string y) {
if (x.size() != y.size()) {
return false;
}
return f(x + x, y) == y.size();
}
int main() {
string x, y;
cin >> x >> y;
cout << g(x, y) << endl;
return 0;
}
```
> 解读 `vector<vector<int>> v(m + 1, vector<int>(n + 1, 0));` 是在构建一个具有 n 个行的二维向量,每个二维向量行都有 n+1个单元格
> 在循环中对每个行和每个列进行迭代,
>> `x[i - 1] == y[j - 1]` 代表 如果当前单元格对应的两个字符相同,就执行
>>> `v[i][j] = v[i - 1][j - 1] + 1;` 操作就是将刚刚两个相同的字符的对应单元格 + 1
>>> `v[i][j]` 表示 x 的前 i 个字符与 y 的前 j 个字符的最长公共子序列的长度。
>> 如果 当前单元格对应的字符不一样 则是取出之前计算过的 v 的最大值
>>> 到这里其实已经看到了一些端倪,二维表建立的目的是为了记录一些东西,记录规则受到字符串 x y 的制约,每个单元格对应着两个字符的 相同次数,两个字符分别从 x y 中取
>>> 当 x y 不相同的时候,记录的值将不是 次数结果 而是当前单元格相邻的左单元和上单元的最大值
#### 判断题
21, f 函数的返回值小于或等于 min(n,m)。(√)
> 最长公共子序列意味着一定会最多有 n 或 m 个字符是匹配的,取决于哪个字符串更短了 满足条件
22, f 函数的返回值等于两个输入字符串的最长公共子串的长度。(x)
> 两者皆要求顺序,但是字串要连续,子序列不需要
> 子序列和字串是不一样的,子序列不要求连序,比如 "abcd" 中 "bd" 是子序列
> 但是在字串中 "abcd" 中 "bcd" 是满足的,"bd" 不满足,不连续了
23, 当输入两个完全相同的字符串时,g 函数的返回值总是 true。(x)
> if 语句会返回 false
#### 选择题
24, 将第 19 行中的 “v[m][n]” 替换为 “v[n][m]”,那么该程序()。
A. 行为不变 B. 只会改变输出 C. 一定非正常退出 D. 可能非正常退出
> D 因为数组会越界
25, 当输入为 “csp-j p-jcs” 时,输出为()。
A. “0” B. “1” C. “T” D. “F”
> g 函数返回的不是一个字符,因此排除 C D
> g 返回的是最长公共子序列的长度和 y 是否一致,题目中的两个字符串 `csp-jcsp-j`和`p-jcs` 的最长公共子序列是 `p-jcs` 为5
> 因此 g 返回的是个 true,Cpp 中 true 是1
26, 当输入为 “csppsc spsccp” 时,输出为()。
A. “T” B. “F” C. “0” D. “1”
> 两个字符串为 `csppsccsppsc` `spsccp`他们的最长公共子序列求解如下
> 我们在 x + x = "c s p p s c c s p p s c" 中找 y = "s p s c c p":
```
x+x: c s p p s c c s p p s c
0 1 2 3 4 5 6 7 8 9 10 11
y: s p s c c p
↑ ↑ ↑ ↑ ↑ ↑
匹配: 1 2 4 5 6 8
和
0 1 2 3 4 5
```
> 最终发现 y 的每个字符在 x+x 里都可以找到字符(保证顺序的情况下)因此最长公共子序列长度为 6
> 选择 D
### (三) 阅读以下程序,完成相关题目。
```
#include <iostream>
#include <cmath>
using namespace std;
int solve1(int n) {
return n * n;
}
int solve2(int n) {
int sum = 0;
for (int i = 1; i <= sqrt(n); i++) {
if (n % i == 0) {
if (n / i == i) {
sum += i * i;
} else {
sum += i * i + (n / i) * (n / i);
}
}
}
return sum;
}
int main() {
int n;
cin >> n;
cout << solve2(solve1(n)) << " " << solve1(solve2(n)) << endl;
return 0;
}
```
假设输入的 n 是绝对值不超过 1000 的整数,完成下面的判断题和选择题。
> 首先对代码进行解析
> solvel1 就不用解析了 直接是 n^2
> solvel2 会将 1到根号(n) 中的每个数字(在这里称呼其为i)内 n % i 的元素进行迭代
>> 这个操作是不是很像 n 在寻找可以整除的数
>> 当 n%i==0 后,又计算了 n/i==i,这一步其实就是看看 i^2是否为n
>>> 到这里,所有元素是可以满足 n%i == 0 同时 i^2==n 的条件了
>>> 在这里让 sum 加上 i^2 也就是平方和
>> 如果不满足 i^2,那么到这里的元素仅仅是可以满足 n%i==0的
>> 在这里让 sum 加上 i^2+(n/i)^2
#### 判断题
27,如果输入的 n 为正整数,solve2 函数的作用是计算 n 所有的因子的平方和。
> 因子就是可以满足这样的公式的 n%因子==0,在代码中确实有这个操作 因此我们需要进一步判断
> 当满足 n%因子==0 的时候 i 其实就是因子,如果 n/i==i 还可以被满足 就代表此选项无误
> 但是是有不满足的时候,比如 n=100 i是[1,10]中的2, 其中 100%2==0 但是 100/2=50 就不满足了
> 因此我们看看不满足的时候它在做什么 `i^2+(n/i)^2`=4+50^2=254 其中有两个平方的值,分别是2 50
> 我们发现 2 和 50 都是因子,因此本函数就是计算n的所有因子平方和的,只不过大部分是一次计算2个因子的平方
> 为什么 n/i==i 就没办法计算2个因子的平方呢?
> 我们可以代入公式求解 10^2 + (100/10)^2 发现这个时候 2 个因子是一样的,都是10
> 因此这个是不可以使用第二个表达式的
> 这个判断题为 正确
28,第 13 ~ 14 行的作用是避免 n 的平方根因子(或 n/1)进入第 16 行而被计算两次。
> 在上一题已经解开了 目的的确是这样的 这个题正确
29,如果输入的 n 为质数,solve2(n) 的返回值为 n²+1。
> 质数只能被 1 和 它自己整除的数
> 可以直接代入一个质数进去,比如 5
> 这个函数会将 1到2(因为根号5约为2.xxx 被强转为2) 作为 i
> 对于 1 sum += 1^2+(5/1)^2 = 1+25 = 26
> 对于 2 不是因子
> sum 最终 满足题目要求 正确
#### 选择题
30,(4 分) 如果输入的 n 为质数 p 的平方,那么 solve2(n) 的返回值为( )。
A. p² + p + 1
B. n² + n + 1
C. n² + 1
D. p⁴ + 2p² + 1
> 比如 n是9 p就是3了 3是质数
> i 的取值为 [1,3]
>> i=1 sum += 1^2+(9/1)^2 = 86
>> i=2 非 9 的因子 不计算
>> i=3 sum += 3^2 = 9
> 最终总结关系为 (3^2) + 1 + (9^2) = n + 1 + n^2
> 最终 B 符合
31,当输入为正整数时,第一项减去第二项的差值一定( )。
A. 大于或等于 0
B. 大于或等于 0 且不一定大于 0
C. 小于 0
D. 小于或等于 0 且不一定小于 0
> 这里的项指的是 main 函数中输出的两个数值
> 设 f(x) 函数是计算 x 的所有因子数平方和
> main 的输出就是 f(x^2) 和 f(x)^2
> 第二项是将因子之和的平方,第一项是平方的因子之和
> 也可以代入解决 在这里 将 x 设为 3 那么 f(3^2) = 86+9=95
> 然后 f(3)^2 = 2 发现出现了小于的情况
> 接下来再代入一些看看
| x | 第一项 `solve2(x²)` | 第二项 `[solve2(x)]²` | 差值 |
|---|---------------------|------------------------|------|
| 1 | 1 | 1 | 0 |
| 2 | 21 | 25 | -4 |
| 3 | 91 | 100 | -9 |
| 4 | 341 | 441 | -100 |
| 6 | 1911 | 2500 | -589 |
✅ **所有情况中:第一项 ≤ 第二项,差值 ≤ 0**
> 得出 从 x=2开始 随着数值的增大 第二项与第一项的差值越来越大,且第二项一致保持比第一项大
> 因此 第一项 - 第二项 属于小于等于 0 的情况 选择 D
而且只有 `n = 1` 时差值为 0,其余都 < 0
32,当输入为 "5" 时,输出为( )。
A. "651 625"
B. "650 729"
C. "651 676"
D. "652 625"
> 直接代入计算就可以了 计算的时候尽量先算好算的然后做排除,比如 f(5)^2
> f(5) = 1^2 + 5^2 = 26; 26^2 = 676 直接算 C 就行
### 三、完善程序(单选题,每小题3分,共30分)
#### (一) 寻找被移除的元素问题
原有长度为n+1、公差为1的等差升序序列;将数列输入到程序的数据时移除一个元素,导致长度为n的升序数组可能不再连续,除非被移除的是第一个或最后一个元素。需要在数组不连续时,找出被移除的元素。
**试补全程序。**
```cpp
#include <iostream>
#include <vector>
using namespace std;
int find_missing(vector<int> &nums) {
int left = 0, right = nums.size() - 1;
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] == mid + (①)) {
②
} else {
③
}
}
return ④
}
int main() {
int n;
cin >> n;
vector<int> nums(n);
for (int i = 0; i < n; i++) cin >> nums[i];
int missing_number = find_missing(nums);
if (missing_number == ⑤) {
cout << "Sequence is consecutive" << endl;
} else {
cout << "Missing number is " << missing_number << endl;
}
return 0;
}
```
> 代码解析
> 这个代码中的 find_missing 就是寻找不连续位置的索引 然后构建出数值
> 仔细观察题目说有序,同时这里还有 left he right,可以猜测这是一个二分查找的逻辑
> 二分查找中会通过每次舍弃右边或左边区间来缩短查找范围
> 在本题中,由于我们要找的是不连续位置,因此所有联系位置所在的区间就是我们要舍弃的
33, ①处应该填()。
A. 1
B. nums[0]
C. right
D. left
> 我们知道对于等差为1的序列,其i索引对应的元素为第一个元素+i
> 比如 [1,2,3,4,5] 中,i为2的元素是3 3=1+i=1+2=3
> 因此这里判断的其实就是这个中间位置以及之前的元素是否是连续的
> 如果是的话 当前位置的元素值一定满足 `nums[mid] == mid + nums[0]` 因此选择 B
34, ②处应该填()。
A. left = mid + 1
B. right = mid - 1
C. right = mid
D. left = mid
> 当我们找到了连续区间为左边界的情况下,我们可以直接将左边边界舍弃,只查找右边边界
> 因此这里排除 B C
> 接下来只需要看看排除的时候是否需要进行 +1
> 如果不加1 是否可行?❌ 不行。mid 已经被确认“正常”,而我们要找的是第一个“异常”位置。把 left 设为 mid,会让 mid 再次被包含进搜索区间,没有排除已知正常的点,可能导致死循环或错误。
> 因此选择 A
35, ③处应该填()。
A. left = mid + 1
B. right = mid - 1
C. right = mid
D. left = mid
> 这个位置就是舍弃右区间了 因此排除 A D
> 这个情况代表的是 不连续位置在左边,因此舍弃的时候,包括 mid 本身在内都可能有问题
> 因此我们进行舍弃的同时要注意将 mid 包含在被查找的区间中
> 因此选择 C,mid会被包含住
36, ④处应该填()。
A. left + nums[0]
B. right + nums[0]
C. mid + nums[0]
D. right + 1
> 让一切结束之后,left 和 right 指向的位置有两个情况
> 第一个就是指向的是不连续位置的索引
> 第二个就是指向序列的最后一个元素的索引
> 我们知道 等差为1的序列中 第一个元素+当前索引就是当前的元素数值
> 因此这里排除 D C
> 二分查找结束的时候 left和right是相同的 因此 A B 应该都可以,但是通常使用 left 来表示结果 因此选择 A
37, ⑤处应该填()。
A. nums[0] + n
B. nums[0] + n - 1
C. nums[0] + n + 1
D. nums[n - 1]
> 当序列一直连续的时候,left 会指向元素末尾索引 也就是 n-1
> 如果想要判断元素是否连续 只需要看看 `nums[0] + n - 1 ` 和函数返回的是否真的一致即可 选择 B
> 为什么不选择 D?因为 会漏判“缺失首元素”的情况
#### (二)(编辑距离)给定两个字符串,每次操作可以选择删除(delete)、插入(insert)和替换(replace)一个字符,求将第一个字符串转换为第二个字符串所需要的最少操作次数。
试补全动态规划算法。
```cpp
#include <iostream>
#include <string>
#include <vector>
using namespace std;
int min(int x, int y, int z) {
return min(min(x, y), z);
}
int edit_dist_dp(string str1, string str2) {
int m = str1.length();
int n = str2.length();
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
for (int i = 0; i <= m; i++) {
for (int j = 0; j <= n; j++) {
if (i == 0)
dp[i][j] = __①__;
else if (j == 0)
dp[i][j] = __②__;
else if (__③__)
dp[i][j] = __④__;
else
dp[i][j] = 1 + min(dp[i][j - 1], dp[i - 1][j], __⑤__);
}
}
return dp[m][n];
}
int main() {
string str1, str2;
cin >> str1 >> str2;
cout << "Minimum number of operations:"
<< edit_dist_dp(str1, str2) << endl;
return 0;
}
```
> 从代码中我们知道它在构建一张表
> 表中有 i 有 j 在不同值的情况下对应的值
| i\j | 0 | 1 |
| :------------: | :------------: | :------------: |
| 0 | | |
| 1 | | |
| 2 | | |
> 意味着当前迭代到的字符 字符串1的i索引字符和字符串2的j索引字符进行配对的一个操作
> 那么当这个表填写完毕之后,右下方的值应该就是我们要的值
> 根据 `dp[i][j] = 1 + min(dp[i][j - 1], dp[i - 1][j], __⑤__);` 我们可以知道这是要我们在表中进行计数
> 应该是将 str1的前i个字符转换为str2前j个字符的最小次数
> 因此最后这个表的右下角单元就是 str1 的整个字符串 转换为 str2 整个字符串需要的最小次数
38. ①处应该填( )。
A. j
B. i
C. =
D. ≠
> 这里是一个初始化动作 i=0 说明现在匹配的过程中,某个字符串没有值,也是字符串地方前0个元素,因为i=0
> 因此变化次数肯定是 max(i,j)
> 这里填 j 符合要求
39. ②处应该填( )。
A. j
B. i
C. =
D. ≠
> 与 38 题是一样的规则 选择 i 也就是 B
40. ③处应该填( )。
A. str1[i-1]==str2[j-1]
B. str1[i]==str2[j]
C. str1[i-1]!=str2[j-1]
D. str1[i]!=str2[j]
> 第三个 if 的时候 i和j都不是0
> 这个时候我们需要考虑两个问题
>> 第一个问题就是越界问题 n m 都是字符串长度,没有减一 因此不能直接使用 排除 B D
>> 第二个问题就是等价关系的判断
>>> 从 else 语句看,else 是无论如何都会有一个 1+ 的操作
>>> 因此 else 的位置肯定是需要操作才会走的位置
>>> 那么 这里什么时候不需要操作?
>>>> 答案是当前字符串的 i 和 j 个字符完全一致的情况
>>>> 因此我们在这里需要进行一个判断,如果两个字符完全一致,就没必要走最后一个 else
>>>> 选择 A
41. ④处应该填( )。
A. dp[i-1][j-1]+1
B. dp[i-1][j-1]
C. dp[i-1][j]
D. dp[i][j-1]
> 40 题说过了 这个 if 里不需要追加数值,直接将上次的计数结果拿过来就行了
> 选择 B
42. ⑤处应该填( )。
A. dp[i][j]+1
B. dp[i-1][j-1]+1
C. dp[i-1][j-1]
D. dp[i][j]
> 这里其实就是 min 舍去统计结果的一个情况
> 我们需要考虑表走到当前单元格的时候,使用的数据可以是来自哪个单元格的
> 分别是 左 上 以及 左上 三个方向 其实也对应题目的三个操作
| 方向 | 对应操作 | 含义 |
|------|----------|------|
| **左:`dp[i][j-1]`** | **插入** | 在 `str1` 末尾插入 `str2[j-1]`,让 `str2` 的第 `j` 个字符匹配 |
| **上:`dp[i-1][j]`** | **删除** | 删除 `str1[i-1]`,继续用 `str1` 前 `i-1` 个字符匹配 `str2` 前 `j` 个字符 |
| **左上:`dp[i-1][j-1]`** | **替换** | 把 `str1[i-1]` 替换成 `str2[j-1]`,然后继续 |
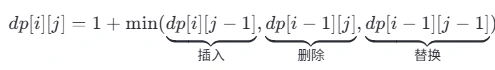
> 这里其实就是做操作步数的累加,1+ 在 40 题说过了原因了,加上谁?
> 当然是加上三个方向的最小值咯!
> 因此这里缺少替换操作 选择 C
------
***操作记录***
作者:[zhao](https://www.lingyuzhao.top//index.html?search=4 "zhao")
操作时间:2025-08-08 19:48:04 星期五 【时区:UTC 8】
事件描述备注:保存/发布
中国 天津市 天津
[](如果不需要此记录可以手动删除,每次保存都会自动的追加记录)