# 大数据平台中 Hadoop 部署
*平台部署知识*
大数据 HDFS / yarn 平台内常用的一些软件的配置,以及部署文档
## 目录
[TOC]
## 前期准备
### 使用终端软件链接 linux 主机
假设在这里我们的 Linux 主机IP是 192.168.0.141,那么就可以直接在终端连接软件中输入 192.168.0.141 IP 并键入用户名和密码就可以登录进去啦。
*PS:如果没有登录成功,可能的原因就是你的路由IP格式不是`192.168.0.x`,例如你的路由是 `192.168.1.1` ,而你的 主机IP 是 `192.168.0.x` 这样的格式,且掩码是24 肯定是访问不通的,因为不你和Linux服务器不属于同一个子网,你可以将你的Linux服务器IP修改为 `192.168.1.x` 而不是 0.x,这里是网络IP相关的知识,确保你的客户端机器所处的局域网内包含Linux主机即可!再简单说就是确保你的客户端机器能够连接到Linux服务器即可!*
文章中使用的软件是 electerm 你也可以选择你喜欢的工具,下面是连接好之后的样子。
### 下载&配置 JDK
首先我们需要在[《JDK下载》](https://www.lingyuzhao.top/?/linkController=/articleController&link=32168969 "《JDK下载》")中前往官方页面,并选择一个需要的 JDK 版本进行下载,注意要下载的是 JavaSE 哦!
#### 将 JDK 上传(顺便把Hadoop也上传一下)
如果下载完毕之后,接下来就需要切换到 Linux的终端存放安装包的目录(假设目录是`/opt/package`)内,然后执行 rz 命令,这样之后,将会自动打开一个文件管理器页面,让你选择要上传的文件!
此时选择好之后,安装包将会存储在 `/opt/package` 目录中,这里的Hadoop 的安装包需要您去自行选择自己的版本哦!
```
root@liming-virtual-machine:~# cd /opt/package/
root@liming-virtual-machine:/opt/package# ll
total 1275904
drwxrwxrwx 3 root root 4096 3月 14 2023 ./
drwxr-xr-x 4 root root 4096 3月 2 2023 ../
-r-------- 1 root root 359196911 3月 14 2023 hadoop-3.2.1.tar.gz
-r-------- 1 root root 194042837 3月 2 2023 jdk-8u202-linux-x64.tar.gz
```
接下来我们直接解压这个 `jdk-8u202-linux-x64.tar.gz` 文件到 `/opt/software` 目录中,如果没有足够的权限请执行`chmod 777 /opt/*` 这将会为你提供足够的权限,当然,最好是使用下面的命令加上一个`sudo` 或者您手动获取到管理员权限,因为修改文件权限为 777 非常危险!
```
# 解压 jdk-8u202-linux-x64.tar.gz 到 /opt/software/ 目录中
sudo tar -xzf jdk-8u202-linux-x64.tar.gz -C /opt/software/
# 解压 hadoop-3.2.1.tar.gz 到 /opt/software/ 目录中
sudo tar -xzf hadoop-3.2.1.tar.gz -C /opt/software/
```
下面是执行之后的命令展示
```
root@liming-virtual-machine:/opt/package# # 解压 jdk-8u202-linux-x64.tar.gz 到 /opt/software/ 目录中
sudo tar -xzf jdk-8u202-linux-x64.tar.gz -C /opt/software/
root@liming-virtual-machine:/opt/package# ll /opt/software/
total 52
drwxrwxrwx 13 root root 4096 2月 29 17:32 ./
drwxr-xr-x 4 root root 4096 3月 2 2023 ../
drwxr-xr-x 9 1001 1001 4096 9月 11 2019 hadoop-3.2.1/
drwxr-xr-x 7 uucp 143 4096 12月 16 2018 jdk1.8.0_202/
```
#### 配置环境变量
修改 `/etc/profile` 文件,这个文件在登录账户之后,其中的脚本代码将会自动执行,因此我们通常会选择在这里进行一些环境变量的初始化动作。
```
# 执行 vim 命令修改 /etc/profile
vim /etc/profile
# 下面是环境变量
export JAVA_HOME="/opt/software/jdk1.8.0_202"
export HADOOP_HOME="/opt/software/hadoop-2.8.3"
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
```
#### 测试 Java 命令是否可用
下面的执行日志代表就是可用,JDK1.8 的配置成功了!
```
root@liming-virtual-machine:/opt/package# java -version
java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
```
## 配置 Hadoop
### 获取配置文件
您可以访问链接 https://github.com/BeardedManZhao/BigData-propertyFiles/tree/core/hadoop 以便获取相关配置,也可以直接在 Hadoop 的配置目录中执行下面的命令,获取到我们写好的配置文件模板!
```
# 进入到 Hadoop 目录
cd /opt/software/hadoop-3.2.1/etc/hadoop
# 下载各种 site 和 env 的配置文件
rm -rf ./core-site.xml
wget https://diskmirror.lingyuzhao.top//1/Binary//github/BigData-propertyFiles/core/hadoop/hdfs%E4%B8%8Eyarn%E7%9A%84%E6%9C%80%E7%AE%80%E5%88%86%E5%B8%83%E5%BC%8F%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6/3.2.1/core-site.xml
rm -rf ./hdfs-site.xml
wget https://diskmirror.lingyuzhao.top//1/Binary//github/BigData-propertyFiles/core/hadoop/hdfs%E4%B8%8Eyarn%E7%9A%84%E6%9C%80%E7%AE%80%E5%88%86%E5%B8%83%E5%BC%8F%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6/3.2.1/hdfs-site.xml
rm -rf ./mapred-site.xml
wget https://diskmirror.lingyuzhao.top//1/Binary//github/BigData-propertyFiles/core/hadoop/hdfs%E4%B8%8Eyarn%E7%9A%84%E6%9C%80%E7%AE%80%E5%88%86%E5%B8%83%E5%BC%8F%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6/3.2.1/mapred-site.xml
rm -rf ./yarn-site.xml
wget https://diskmirror.lingyuzhao.top//1/Binary//github/BigData-propertyFiles/core/hadoop/hdfs%E4%B8%8Eyarn%E7%9A%84%E6%9C%80%E7%AE%80%E5%88%86%E5%B8%83%E5%BC%8F%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6/3.2.1/yarn-site.xml
```
当然,下载之后是按照 192.168.0.141 的IP 和 `liming141` 的主机名来进行设置的,您需要查看这些配置,将他们修改为您自己的主机情况。
### 修改 hadoop-env.sh 和 work 文件
我们需要通过下面的操作告诉 Hadoop 我们的 Java 环境变量在哪(它似乎在这个时候不会自己找环境变量,有点讨厌)
```
# 在 hadoop-env.sh里面直接插入这个行就可以啦
export JAVA_HOME="/opt/software/jdk1.8.0_202"
```
如果不配置可能会出现下面的错误
```
root@liming-virtual-machine:/opt/software/hadoop-3.2.1/sbin# ./stop-all.sh
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Stopping namenodes on [liming141]
liming141: ERROR: JAVA_HOME is not set and could not be found.
Stopping datanodes
localhost: ERROR: JAVA_HOME is not set and could not be found.
Stopping secondary namenodes [liming-virtual-machine]
liming-virtual-machine: ERROR: JAVA_HOME is not set and could not be found.
Stopping nodemanagers
localhost: ERROR: JAVA_HOME is not set and could not be found.
```
然后我们需要修改 works 文件,这个文件就是存储集群中所有主机 IP 的文件,这是为了让Hadoop集群知道自己的集群里有哪些主机,如果您有额外的主机,直接在这里加IP就可以了,如果没有其它主机不需要加IP或主机。
### 修改启动脚本
我们现在下载好了所有的配置文件,接下来我们需要将启动脚本进行修改,在里面加上一些配置,首先需要进入到脚本目录
```
# 进入到 Hadoop 的脚本目录
cd /opt/software/hadoop-3.2.1/sbin
```
**注意 如果不配置这里会有可能出现下面的错误!!!**
```
root@liming-virtual-machine:/opt/software/hadoop-3.2.1/sbin# ./start-all.sh
Starting namenodes on [liming141]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [liming-virtual-machine]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
```
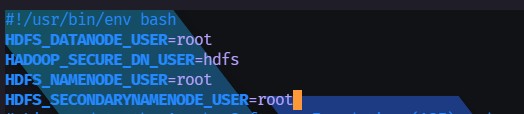
#### *-dfs.sh
在 HDFS 的启动与终止脚本中的第二行插入下面的四个语句
```
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
```
#### *-yarn.sh
在 YARN 的启动与终止脚本中的第二行插入下面的三个语句
```
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
```
### 格式化HDFS文件系统
```
cd /opt/software/hadoop-3.2.1/bin/
./hdfs namenode -format
```
如果你是在特定的 Hadoop 配置目录下工作,你可能需要指定配置目录的路径,例如:
```
./hdfs namenode -format -config /path/to/your/hadoop/config/directory
```
## 启动测试
```
cd /opt/software/hadoop-3.2.1/sbin/
./start-all.sh
```
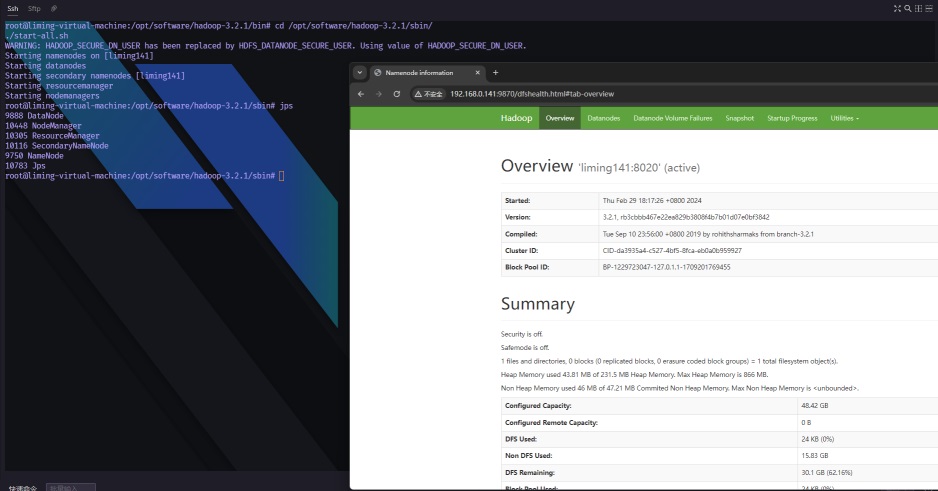
下面是我们启动 Hadoop 并访问 Hadoop Web 页面的结果
------
***操作记录***
作者:[root](https://www.lingyuzhao.top//index.html?search=1 "root")
操作时间:2024-02-29 18:19:21 星期四
事件描述备注:保存/发布
中国 天津
[](如果不需要此记录可以手动删除,每次保存都会自动的追加记录)
------
***操作记录***
作者:[root](https://www.lingyuzhao.top//index.html?search=1 "root")
操作时间:2024-03-02 09:13:09 星期六
事件描述备注:保存/发布
中国 天津
[](如果不需要此记录可以手动删除,每次保存都会自动的追加记录)